.svg)
.svg)


What does ecommerce product data management actually solve (beyond a clean catalog)? [toc=1. Why It Matters]
A merchandiser I sat with last quarter described her catalog work as "drinking from a fire hydrant." She was not exaggerating. She had eleven thousand SKUs, four sales channels, and no single place where a product's data was simply correct.
Ecommerce product data management is the system for collecting, organizing, and activating every attribute attached to your SKUs, so that data is accurate everywhere it touches a customer. Done right, it stops wrong-part returns, kills the manual re-listing tax across channels, and turns your catalog into something you can sell against. The real win is activation, not storage.
🧯 The "data-cleanup year" nobody warns you about
Most operators hit a stage where messy SKU names, non-standard size breaks, and disconnected systems quietly block selling. I call it the data-cleanup year. You are not launching products. You are reconciling them.
That auto-parts operator's mismatched distributor attributes broke her fitment filter. Customers ordered brake kits that did not fit their car. Returns climbed. The catalog was "clean" in the sense that every field was filled, but it was not activated, so it could not actually sell. This is the exact gap a unified approach to drowning in data is built to close.
📦 Storage is table stakes. Activation is the point.
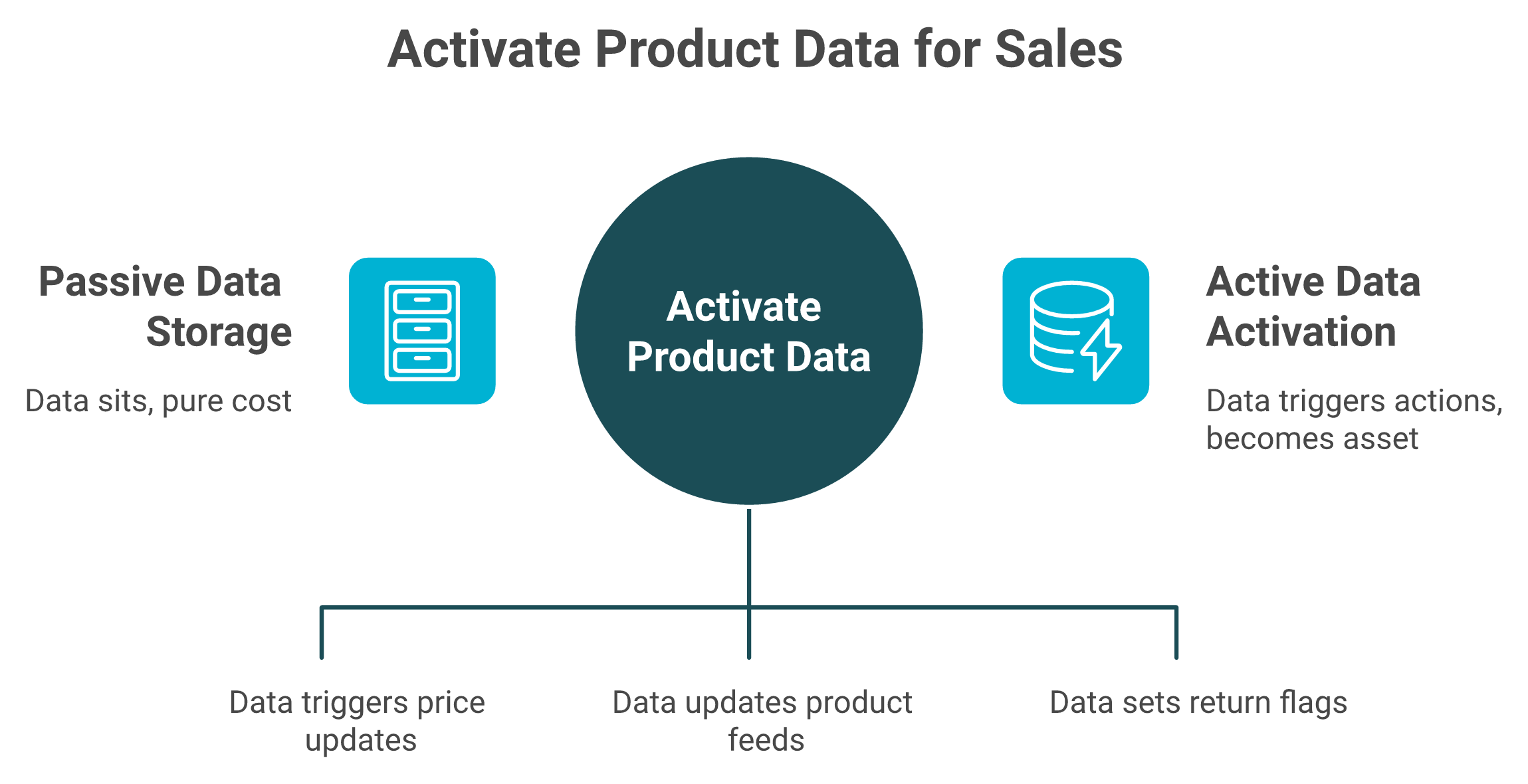
Here is the part the standard guides get backwards. They treat product data management as filing. Organize, store, secure, repeat. Shopify's own data management guidance frames it as collecting, organizing, storing, and analyzing the information your business gathers.
I think the analyzing is where the money lives, and most stores stop before they get there. Data that just sits in a database is a cost. Data that triggers an action (a price correction, a feed update, or a flag on a returning SKU) is an asset.
Product master data management automates data processes, reduces manual intervention, and minimizes errors across the catalog. That matters because manual intervention is exactly what eats your team's week.
⚡ What this changes on Monday
The reframe is simple. Stop asking "is my catalog tidy?" Start asking "what does my product data let me do?" Clean attributes mean accurate feeds. Accurate feeds mean visibility. Visibility means sales.
This is the gap we built Luca to close. Most analytics tools added AI on top of dashboards. Luca is AI sitting on your data, so the catalog stops being a passive archive and starts surfacing what needs attention. The principle holds even if you never touch our product: normalize on ingestion, then activate.
PDM vs PIM vs MDM vs a feed tool: what's the difference and which do you need? [toc=2. PDM vs PIM vs MDM]
Founders waste real money here. They buy a master data management platform when a bulk editor would have done the job, or they run on spreadsheets six months past the point where that stopped working. The acronyms are not the hard part. Matching the tool to your stage is.
Here is the plain-English version. PDM (product data management) organizes and controls product data. PIM (product information management) enriches and syndicates it to channels. MDM (master data management) governs all master data company-wide. A feed tool formats data for Google Shopping and marketplaces. Most stores under five million in revenue do not need MDM, and many do not yet need a full PIM.
🗂️ The four categories, side by side

PDM is best understood as a comprehensive system for organizing and controlling product information across its lifecycle. That is accurate. My caution is that the lifecycle framing makes everything sound like it needs heavy software.
⚠️ My contrarian read: PIM is oversold below a certain stage
The standard evaluation checklist (data hub, data model, workflows, integration, and scalability) is genuinely useful, and worth keeping. But it is also a sales funnel. Vendors apply enterprise criteria to a store doing eighty thousand a month.
One operator I spoke with integrated four separate systems before she needed any of them. Her words stuck with me: it "cost me a lot of time and a lot of money because I could not do everything on my own." That is the over-tooling tax, paid in cash and calendar. Choosing the right ecommerce management software at the right stage saves both.
💸 What operators actually run into
"Before deciding on any tool, consider if you have another data source? Even if it is a spreadsheet, what is your data volume? And how often do you need refreshes?"
— u/un50zbg5, r/shopify Reddit Thread
That comment is the right instinct. Diagnose volume and refresh frequency first, then buy. Luca sits a layer above this debate (it reasons over whatever data you connect), so it is not your PIM and I will not pretend otherwise. Pick the storage tier that fits your stage, then decide what reads the data.
What product data should you collect, and how do you standardize attributes you don't control? [toc=3. Data to Collect and Standardize]
The hardest data problem in ecommerce is not deciding what to collect. It is forcing data from fourteen different suppliers, none of whom agree on naming, into one standard your store can actually use.
Collect the core five: identifiers (SKU, GTIN), descriptive attributes, media, pricing and inventory, and category-specific attributes like fitment or size breaks. Then normalize every source into one naming standard at the moment it enters your system. Standardize on ingestion, or you inherit your suppliers' chaos forever.
📋 The five attribute groups to capture
- Identifiers: SKU, GTIN, MPN, and barcode. The keys everything else hangs on.
- Descriptive attributes: title, description, brand, material, and specs.
- Media: images, video, spec sheets, and sizing diagrams.
- Pricing and inventory: price, cost, stock, location, and supplier.
- Category-specific attributes: fitment (make, model, year, and trim), size breaks, and compatibility.
Get group five wrong and you get returns. The auto-parts operator's "retail weeks 554, 332" were non-standard across every brand she stocked. Those tiny convention mismatches are what break a fitment filter.
🛠️ How to standardize what you don't control
You will rarely get a clean API from a distributor. So the standard has to live on your side, applied the moment data lands. Here is the sequence I have watched work.
- Define one canonical schema. One name for "color," one format for "size," and one fitment structure.
- Map each source to it on ingestion. A transformation step, not a manual cleanup later.
- Validate before publish. Reject rows that fail the schema instead of letting them spread.
- Hand the schema to suppliers. Give them your field names so the next file arrives closer to clean.
There is a deeper point here on quality. As one operator put it, the brands "won't tell you what's in the shock and how they behave, it's all marketing speak, so we have to do the work." Your descriptive data is often more honest than the manufacturer's. That work is a moat, and it is exactly the kind of product management leverage that compounds.
💸 What store owners say about the mess
"I run a small ecommerce store. I've been looking at analytics product recommendation apps but honestly, hard to tell which ones are actually good, pricing feels expensive long-term, and reviews are mixed and sometimes feel fake."
— u/Anonymous, r/ShopifyeCommerce Reddit Thread
The skepticism is earned. The right hygiene layer covers titles, descriptions, and schema as the foundation that builds trust and search performance. My add: hygiene without normalization on ingestion is a treadmill. This is exactly what Luca does at the front door, normalizing and standardizing data as it comes in, so you skip the cleanup year. Plug in, ask, act.
How do you keep product data consistent across Shopify, Amazon, and every channel? [toc=4. Cross-Channel Consistency]
The fifteen hours a week an operator loses to manual re-listing is the symptom. The disease is having no single master that every channel reads from.
Consistency comes from a single source of truth that pushes outward to channels, never from editing each channel by hand. Pick one system as the master, normalize definitions so "in stock" and "price" mean the same thing everywhere, then syndicate. Edit once, publish everywhere.
🎯 One master, syndicated outward
The argument is simple. If three channels each hold their own version of a product, you have three sources of truth, which means you have none. Drift is inevitable. A price changes in one place and not the others.
A PIM organizes, syncs, and distributes product data across channels for accuracy. The mechanism that matters is direction. Data flows from one master to many endpoints, not peer to peer, which is the backbone of any serious e-commerce tech stack.
📉 The manual-export trap
I have watched this break at serious scale. One operator running two hundred million in GMV described the early days as "so Excel based, pretty much most of the business was tied up with reporting on these manual tools, exports from Shopify, exports from returns system." Big revenue did not save them from the export treadmill.
That is the cost of vertical silos: tracking data only inside Shopify-only or Amazon-only views. The real leverage is horizontal, connecting sources so a single change propagates everywhere, the same principle behind solid ecommerce website analytics.
🔍 Why discovery now depends on this
There is a 2026 wrinkle. Product feeds are becoming core search infrastructure, shaping how brands appear across organic, Shopping, and AI-driven discovery. One operator put the stakes plainly: "if you are not in Google Shopping, you won't be visible anywhere else, you may be invisible in the LLM." Inconsistent data means broken feeds, and broken feeds mean invisibility.
💸 What the broken version looks like
This is exactly where multi-channel sellers get burned by tools that promise unification and do not deliver:
"Triple Whale shows orders from external marketplaces as if they were real conversions even though these orders never go through our Shopify store. Completely fake data. If you're a serious seller, especially if you sell on multiple channels, avoid Triple Whale."
— XTRA FUEL, 1/5 stars Triple Whale Trustpilot Verified Review
"It has been unable to deliver on the promise to provide any insights or accurate data to our business, and we end up reverting back to direct data sources like Meta, Shopify, Recharge."
— Matt Huttner Triple Whale Trustpilot Verified Review
Reverting to raw sources is the tell. When the unified layer is wrong, the founder goes back to manual triangulation. Luca's answer is a single source of truth with one consistent schema across connected sources, so marketing, finance, and ops argue from the same numbers instead of three conflicting exports. Honest caveat: that only helps once your data is actually flowing in. Connect first, then trust the single view.
When does a spreadsheet stop working: what's the SKU-and-channel maturity ladder? [toc=5. Maturity Ladder]
A founder asked me last month whether she needed a PIM. She had nine hundred SKUs on one Shopify store. My honest answer surprised her: not yet, and buying one now would waste cash she needed for inventory.
A spreadsheet works until roughly 1,000 SKUs on one channel. Add metafields and a bulk editor through about 3,000 SKUs and two channels. Past 5,000 SKUs across three or more channels, manual maintenance breaks and a PIM earns its cost. At 10,000-plus SKUs with no supplier API, a headless PIM stops being optional. Diagnose by SKU count and channel count, not by fear of missing out.
🪜 The maturity ladder, by SKU and channel count
A clear-eyed read of the software tiers across these tools is useful once you know your rung, and it pairs well with a wider view of ecommerce analytics platforms.
⚠️ The over-build trap costs more than the spreadsheet
Here is where I take a position. The expensive mistake is not staying on spreadsheets too long. It is buying a heavy system too early.
One founder I learned from spent around ten million dollars building a proprietary data system. His verdict later was brutal: large language models came along and were "ten times better than you can be even after spending ten million." Building ahead of your stage is a real way to burn cash, which is why calculating working capital before you buy matters.
💸 What operators say about outgrowing the basics
"We started on spreadsheets, moved to a PIM way too early on someone's advice, and it sat half-used for a year. Should have waited until we actually had the SKU count to justify it."
— u/Tooth_Fairys_Slave, r/ecommerce Reddit Thread
The fix is sequencing. Buy storage when the storage hurts, not before.
Luca sits a rung above all of this, as the intelligence layer that reads whatever data you have unified. Honest caveat: it needs enough data to reason against, so a 200-SKU store on day one is not its moment. Climb the ladder first, then put something smart on top.
What should you look for when choosing a product data management system? [toc=6. How to Choose a System]
Most "best PDM software" lists rank tools by how many fields they store. That is the wrong sort order. Storage is the floor, not the differentiator.
Judge any product data system on seven things: an intelligence layer that reads the data, flexible attribute modeling, validation on ingestion, a digital asset (media) manager, channel syndication, workflow automation, and scalability to your SKU ceiling. Most vendors sell storage and call it management. The capability that separates a filing cabinet from a system is whether anything intelligent happens to the data after it lands.
🧠 The seven criteria, ranked by what moves money
- Intelligence and activation layer. Does anything reason over the data, or does it just hold rows? This is where Luca lives: an AI layer over your data warehouse that extracts the relevant data for a question, predicts on history, simulates scenarios, finds root cause, flags weak and strong areas, and pushes reports to Slack or email. Most analytics tools added AI on top; we built Luca as AI.
- Flexible attribute and taxonomy modeling. Custom attributes, variants, hierarchies, fitment, and size breaks without hacks.
- Validation and normalization on ingestion. Catches bad data at the door so it never spreads.
- Digital asset management (DAM). Images, video, and spec sheets tied to the SKU, not scattered in folders.
- Channel syndication. One master pushing to Shopify, Amazon, and Google Shopping.
- Workflow automation and governance. Approvals, roles, and an audit trail a small team can run.
- Scalability. Holds up from 1,000 to 50,000-plus SKUs without re-platforming.
The common must-have feature lists and the standard selection criteria (data hub, model, workflows, integration, and scalability) cover items two through seven well, and they map cleanly onto a modern e-commerce tech stack.
⚠️ Why "storage-era" tooling quietly fails you
I might be slightly biased here, but the pattern is consistent. Operators tell me their reporting tools have fallen behind on how AI-ready they are, and that legacy data tables (some literally structured like it is 1980) make every question harder.
The payoff of the intelligence layer is volume you cannot match by hand. One team I know went from watching five session recordings a week to having AI read five thousand a day. That is the gap between storing data and using it, and it is the heart of agentic AI for founders.
💸 What buyers say in the demo trap
"Triple Whale promises a lot in the demo. Six months in, half our team had stopped opening it because the numbers never matched our source platforms."
— Sourcefuel Triple Whale Trustpilot Verified Review
Take this checklist into the demo. Ask vendors to prove the intelligence claim on your data, not a polished sample.
Where does AI actually help with product data, and where will it wreck your catalog? [toc=7. AI: Help vs Harm]
Most people now treat AI as a magic catalog button. They are half right, and the half they get wrong is the expensive half.
AI is excellent at the grind: enriching descriptions, normalizing attributes, and turning a two-week data task into ninety seconds. It is dangerous as your final quality check. Leave a human in the loop on anything customer-facing, because unsupervised AI will confidently publish a twenty-thousand-dollar bike with the derailleur on the wrong wheel. Use AI to draft and detect, keep people on the final check.
✅ Where AI genuinely earns its keep
The upside is real, and I have watched it land. Large-scale data manipulation that used to take two weeks now finishes in ninety seconds with the right model. Enrichment, translation, and attribute mapping are exactly the repetitive work AI eats happily.
Modern tools now automate catalog enrichment and SEO-ready content across Shopify, Amazon, and Walmart. That is a legitimate use. The data is structured, the stakes per field are low, and a human can spot-check the batch, which is the spirit of how AI can actually help you run the business.
❌ Where it quietly wrecks things
Here is the part the category avoids saying. The standard read on AI gets this backwards: the risk is not bad drafts, it is unsupervised publishing.
A large bike brand let AI run creative autonomy and published a premium road bike with the rear derailleur placed on the front wheel. The lesson an operator drew from it stuck with me: "Don't remove the QA. Don't let the AI be the QA." I have seen native AI forecasting features hallucinate so badly that teams shut them off.
⚠️ The rule: draft with AI, decide with humans
My read right now is simple. Garbage in, garbage out still rules, and confidence is not accuracy. AI should propose, a person should approve anything a customer sees.
This is exactly how we built Luca for product management. Its actions are confidence-gated, so it earns autonomy by demonstrated competence and keeps you in control of high-stakes moves. That is the difference between AI-native reasoning and a dashboard with AI sprinkled on top.
💸 What operators say about trusting the automation
"I've been burned by tools that auto-update product data and quietly overwrite my manual fixes. Now I never let anything publish to live without a human looking first."
— u/Available-Wing-1185, r/shopify Reddit Thread
That instinct is correct. Automate the draft, never the final approval.
How does product data feed SEO, Google Shopping, and AI search discovery in 2026? [toc=8. Discovery and GEO]
Your product data is no longer just inventory. It is now your search infrastructure, and most stores still treat it like a back-office chore.
Clean titles, original descriptions, accurate attributes, and valid product schema decide whether you surface in organic results, Google Shopping, and AI answers. The chain is direct: bad attributes mean bad feeds, bad feeds mean invisibility. And if you are not in Google Shopping, you are likely invisible in the AI engines too.
🔗 The data-to-discovery chain
Think of it as a single pipe. Attributes feed the product feed. The feed feeds Shopping and the engines. Break the first link and everything downstream goes dark.
Product feeds are becoming core search infrastructure, shaping how brands appear across organic, Shopping, and AI-driven discovery. One operator put the stakes bluntly: "if you are not in Google Shopping, you won't be visible anywhere else, you may be invisible in the LLM." Discovery now starts with your feed, and so does a smart stack of AI tools for Shopify owners.
🛠️ The attribute and schema checklist
Here is the practical layer, the part you can act on this week.
- Titles built from real attributes (brand, product, and key spec), not keyword stuffing.
- Descriptions written by you, since manufacturer copy is duplicated everywhere.
- Structured attributes (size, material, and compatibility) filled completely.
- Product schema (JSON-LD) valid, so engines read price, availability, and reviews.
Guidance on ecommerce product page SEO reinforces that clean, complete product data is the foundation, not the afterthought, and it ties directly into solid ecommerce website analytics.
⚠️ Chase the durable lever, not the algorithm
I want to be honest about uncertainty here. SEO is a shifting landscape, and some operators rationally choose not to chase it because it feels fragile. I get that.
My take: the durable move is clean feeds and complete attributes, not algorithm tricks. One team auditing AI visibility sent around eighty prompts to each engine and got over thirty thousand result rows back. That is the new shelf, and your product data is what stocks it. Luca helps here only at the edges (surfacing which products underperform on discovery), so I will not overclaim it as an SEO tool.
What does clean product data do to your margins and returns? [toc=9. Impact on Profit]
A founder slid his laptop across the table and showed me a hero SKU. Seventy-two percent gross margin. He was glowing. Then we ran the real numbers, and the glow faded.
Dirty product data costs you twice: in returns from wrong-spec orders, and in support time answering questions your data should answer. One knife set drove around thirteen thousand dollars a year in customer-service costs, which works out to roughly one dollar forty-five per unit. Clean attributes cut returns, shrink support load, and surface the SKUs quietly losing you money.
📉 The situation: a margin that looked great
The seventy-two percent figure was gross margin, the number after cost of goods only. It ignored everything that happens after the sale. Most founders stop reading their P&L right there.
That is the trap. Gross margin is a headline, not a verdict. The real question is contribution margin, what is left after you allocate the messy, per-order costs too, which is exactly the kind of unit economics tracking most stores skip.
⚠️ The complication: the costs hiding in bad data
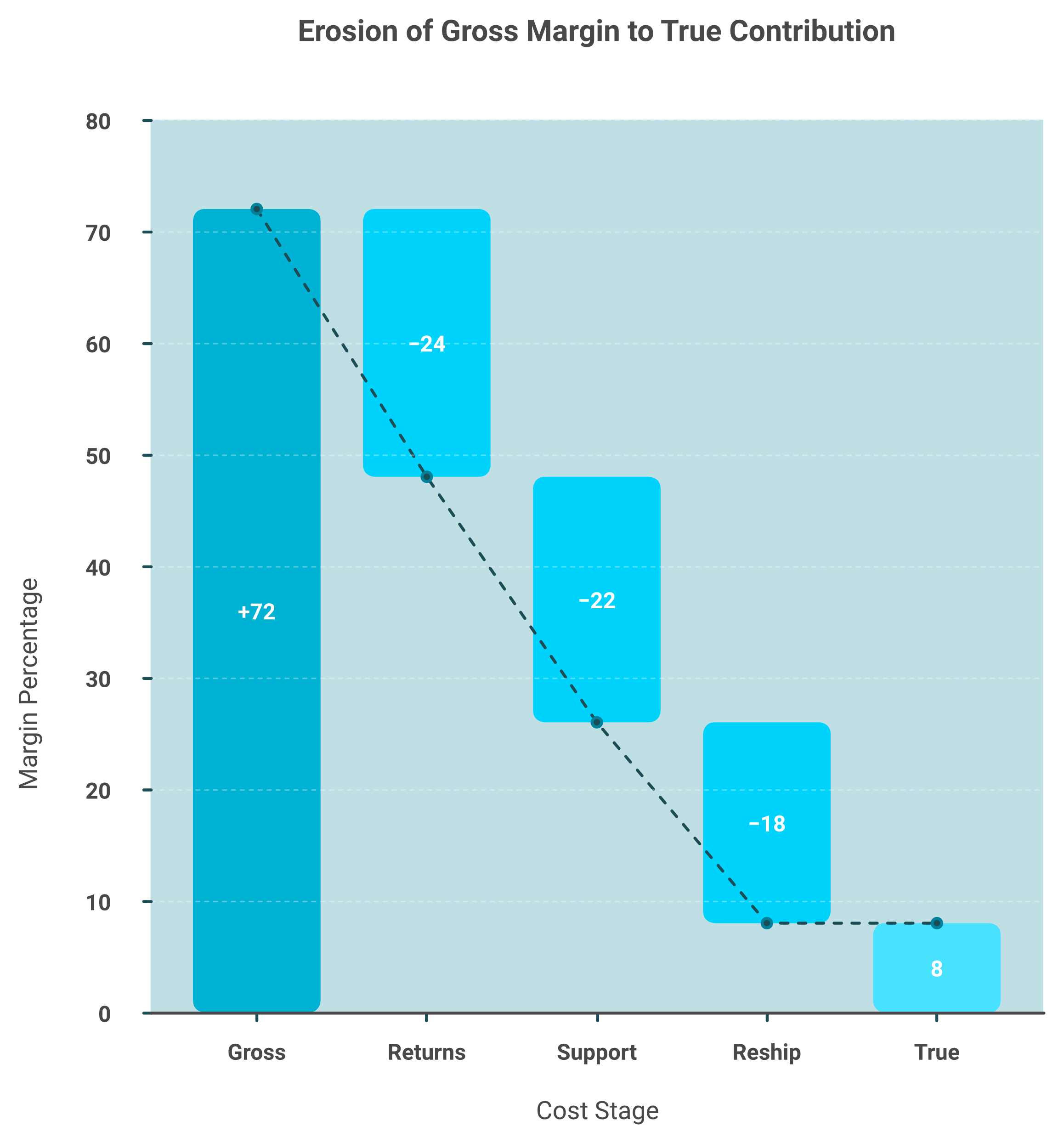
We allocated it line by line. Returns from spec confusion. Support tickets answering questions the product page never answered. Reship costs. True contribution on that "72 percent" SKU landed near eight percent.
The pattern is industry-wide. Retailers lose over a trillion dollars a year to revenue distortion tied to poor inventory accuracy. Bad data is not a tidiness problem. It is a margin problem, and it is why true profitability beats platform ROAS.
✅ The resolution: data that flags the leak early
The fix is making these costs visible per SKU before they compound. When you can see that one product generates triple the support tickets, you fix the page, the attributes, or the listing.
This is exactly the cross-functional read we built Luca to do. It blends product, marketing, and finance data to surface true per-product profitability and true CAC (customer acquisition cost), not the platform-reported version. It is the difference between a dashboard that shows gross margin and an analyst that tells you the eight-percent truth, the heart of real sales performance analysis.
💸 What operators say about the hidden costs
"Triple Whale shows orders from external marketplaces as if they were real conversions... Completely fake data. If you're a serious seller, especially if you sell on multiple channels, avoid Triple Whale."
— XTRA FUEL, 1/5 stars Triple Whale Trustpilot Verified Review
"It has been unable to deliver on the promise to provide any insights or accurate data to our business, and we end up reverting back to direct data sources."
— Matt Huttner Triple Whale Trustpilot Verified Review
Inaccurate data does not just mislead. It sends you back to manual triangulation while the real margin leak keeps bleeding. The fix starts with honest financial management built on data you can trust.
What's the practical workflow to fix your product data this quarter without a data team? [toc=10. Your 90-Day Workflow]
You do not need a fleet of data-entry hires to fix this. You need a sequence, run over one quarter, with discipline at the front door.
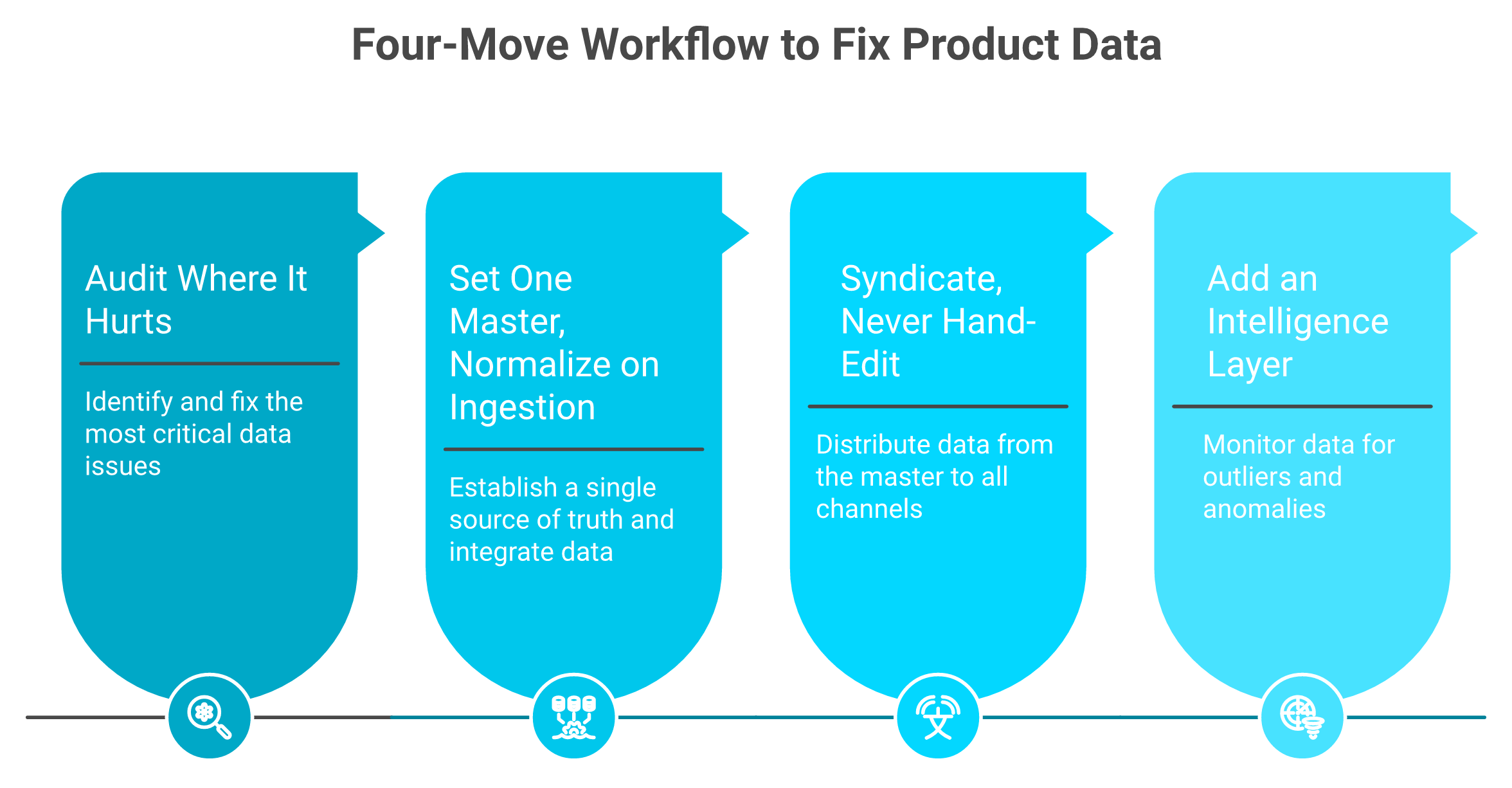
Run it in four moves. Audit your worst attribute gaps where returns cluster. Set one system as the master and normalize every source into it on ingestion. Syndicate to channels from that master, never by hand. Then put an intelligence layer on top to watch for drift and surface the SKUs costing you money.
🛠️ The four-move workflow
- Audit where it hurts. Pull your top returns and support tickets. Trace each to a missing or wrong attribute. Fix the worst offenders first, not the whole catalog.
- Set one master and normalize on ingestion. Pick the system that holds truth. Map every supplier feed into one schema as data enters, so cleanup stops being a yearly event.
- Syndicate, never hand-edit. Push from the master to Shopify, Amazon, and your feeds. One change, every channel.
- Add an intelligence layer. Put something on top that monitors the data and pings you when something breaks.
🧰 A small-team adoption trick
Here is a human detail that matters more than the tooling. One operator named their internal AI helper "Harry" to lower staff resistance, and it now fields around a hundred repetitive questions a day from new hires.
Naming it made the team adopt it. I have watched adoption fail not on capability, but on resistance. Lower the resistance and the tool actually gets used, which is the practical side of agentic AI for ecommerce founders.
✅ Where the intelligence layer fits
Step four is where Luca lives, and I will be specific so it is not a feature dump. It scans your connected data around the clock and pings you when ROAS dips, inventory falls below a threshold, or CAC spikes. You can tell it, in plain English, to send a weekly CAC report with the reasoning shown.
That is the junior data analyst you cannot afford to hire, working nights. Honest scope: it needs enough connected data to reason against, so a brand-new store is not its moment. Once you are connected, it works much like the marketing analysis and automation layer that unifies your sources.
💸 What operators say about getting started
"Honestly the best thing we did was stop trying to fix everything at once and just clean up the SKUs that were actually generating returns. Took a weekend, not a quarter."
— u/Tooth_Fairys_Slave, r/ecommerce Reddit Thread
That is the right energy. Start where it bleeds, not where it is tidy.
🔮 The question I'm sitting with
Here is what I think shifts by 2027. As AI engines become the shelf, the brands that win discovery will be the ones whose product data is clean enough for a machine to trust without a human in the loop.
So my open question to you: if an AI had to sell your catalog tomorrow using only your attributes, would it get the product right? If you are not sure, that is the project for this quarter. I would genuinely like to hear what your audit turns up, so feel free to start that conversation with us.

.webp)

.svg)
.webp)

.png)
