Ecommerce Data Management: Lifecycle, Integration Patterns, Identity Resolution, and AI Readiness
13
mins read
In this article
TL;DR
Ecommerce data management in 2026 unifies five streams (product, customer, transactional, behavioral, and inventory) into one reasoning layer that AI agents can act on. Most €1M to €20M brands break at the normalization stage, where SKU naming and attribution drift compound into the dreaded data cleanup year. Identity resolution gaps cause brands to misidentify up to 23% of their highest-value customers, distorting CAC, LTV, and retention budgets. PIM, CDP, MDM, and warehouse each own a distinct stream; most DTC stacks need CDP plus warehouse first, MDM only past €20M. A defensible 90-day AI activation roadmap runs three phases: connect streams, normalize and resolve identity, then activate proactive alerts and reports. Triple Whale plus Wayflyer leaves a 10 to 15 hour weekly reconciliation gap that a unified AI Co-Founder stack closes inside one conversation.
Q1: What Exactly Is Ecommerce Data Management in 2026, and Why Has the Definition Changed? [toc=1. Definition Shift]
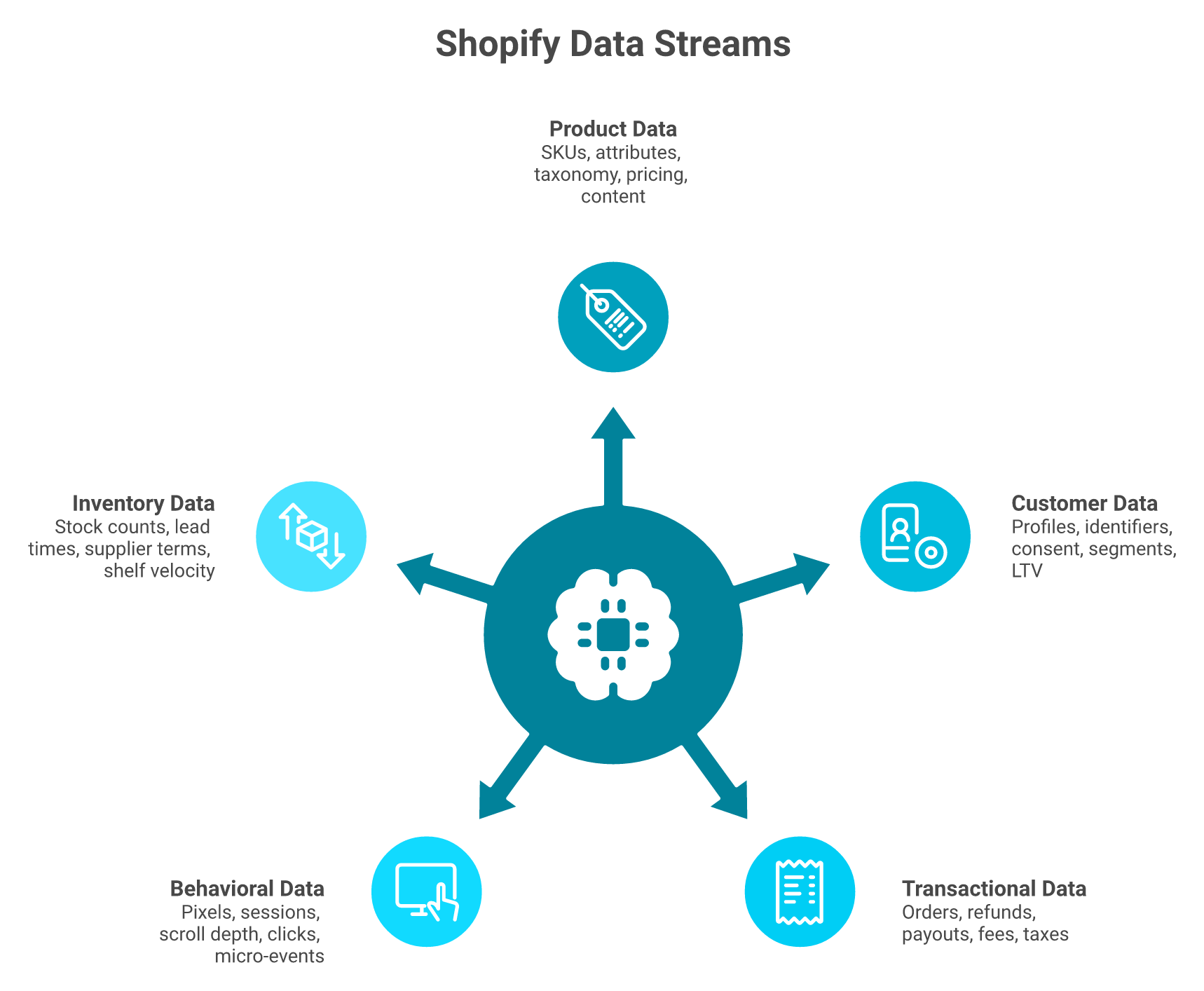
The five streams under every Shopify store
If you run a DTC brand between €1M and €100M, you are sitting on five raw streams whether you've named them or not.
Product data: SKUs, attributes, variants, taxonomy, pricing, and content
Customer data: profiles, identifiers, consent, segments, and lifetime value
Transactional data: orders, refunds, payouts, gateway fees, and taxes
Behavioral data: pixels, sessions, scroll depth, clicks, and micro-events
Inventory data: stock counts, lead times, supplier terms, and shelf velocity
Saras Analytics' May 2026 strategic guide names the same five streams and points out that quality SLAs differ for each one, which is why a single "data quality score" is meaningless.
The five streams every Shopify store already generates, unified into one reasoning layer where AI can act.
Why the definition shifted in the last 18 months
Until late 2024, "data management" mostly meant "ETL data into a warehouse and build dashboards on top." That is no longer the bar. Virto Commerce's 2026 MDM guide reframes the discipline as the "single source of truth layer above PIM and CDP," explicitly built so AI agents can reason across entities.
The mechanical change is small. The implication is huge. Your data isn't a reporting asset anymore. It's the substrate for every automated decision that follows. For a deeper look at the broader stack, see our breakdown of the modern e-commerce tech stack.
"Drinking from a fire hydrant"
Ken Price at Blake Mill described managing merchandising data without a unified layer as "drinking from a fire hydrant." That phrase shows up in operator interviews repeatedly. The pain isn't that data is missing. The pain is that there's too much of it pointing in different directions.
After looking at thousands of DTC P&Ls, what jumps out is this: the brand that rebuilt its data foundation in 2024 is moving 3x faster in 2026 than the one still triangulating CSVs. We've covered this pattern in why e-commerce founders are drowning in data.
What this means on Monday morning
We built Luca because the alternative was hiring a junior data analyst, a BI engineer, and a fractional CFO just to answer "what's my true contribution margin by channel this week." Luca normalizes the five streams on ingestion, holds them in a single reasoning layer, and answers cross-functional questions in plain English. No SQL. No dashboard-building. Cohort-level vigilance without the cohort-level dashboard. Read the full AI Co-Founder explainer for the architectural detail.
"Triple Whale shows orders from external marketplaces as if they were real conversions, even though these orders never go through our Shopify store. Completely fake data." XTRA FUEL Triple Whale Trustpilot Verified Review
That review is exactly why definitions matter. A reporting tool that misrepresents one stream poisons every decision downstream.
Q2: What Does the Ecommerce Data Lifecycle Actually Look Like, From Capture to Activation? [toc=2. Data Lifecycle]
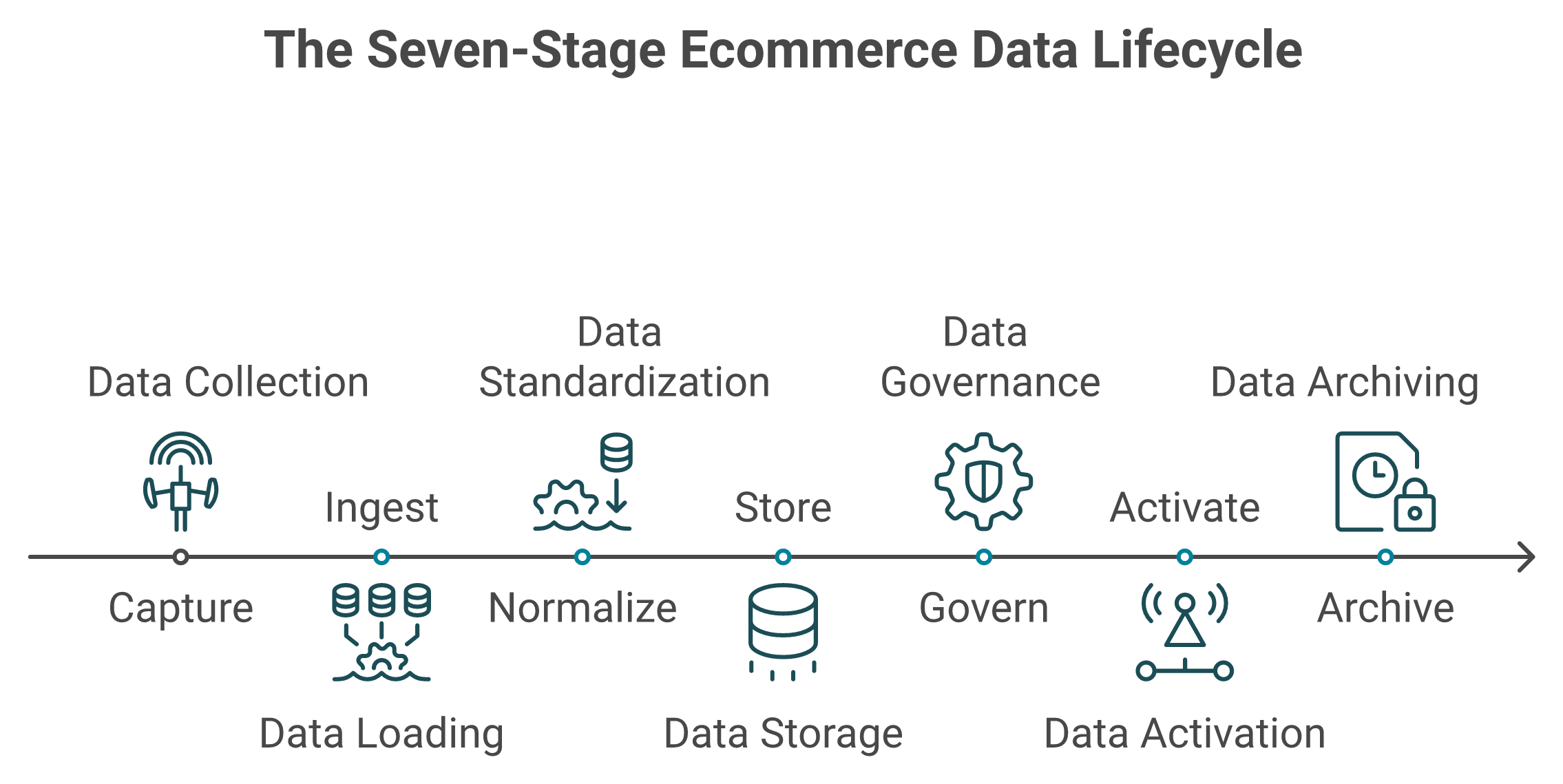
The ecommerce data lifecycle has seven operational stages: capture (Shopify, Meta, GA4), ingest (ETL connectors), normalize (schema mapping), store (warehouse or lakehouse), govern (quality and access rules), activate (reverse-ETL into Klaviyo and Meta), and archive. Most €1M to €20M brands break at stage three, normalization, because SKU naming and attribution drift compound silently. Skipping the "data cleanup year" requires normalizing on ingestion, not after.
The seven-stage ecommerce data lifecycle, with the two stages where most mid-market DTC brands break.
The seven stages, with where brands actually break
Ecommerce Data Lifecycle: Seven Stages and Failure Points
Stage
What happens
Tool examples
Where it breaks
1. Capture
Pixels, webhooks, and API pulls fire on every event
Shopify, Meta CAPI, Klaviyo SDK
Pixel misfires, consent gaps
2. Ingest
Raw rows land in the warehouse
Fivetran, Stitch, Airbyte
Connector latency, schema drift
3. Normalize
Field names, currencies, and taxonomies aligned
dbt, Coalesce, custom SQL
SKU rename chaos, currency drift
4. Store
Warehouse or lakehouse holds modeled data
Snowflake, BigQuery, Databricks
Cost creep, query timeouts
5. Govern
Quality, access, and lineage enforced
Monte Carlo, dbt tests
Nobody owns the rules
6. Activate
Reverse-ETL pushes audiences and triggers
Hightouch, Census
Stale audiences, attribution lag
7. Archive
Cold storage, retention, and deletion
S3 Glacier
GDPR debt, "we kept it forever"
Where the wheels come off
Stage three kills most mid-market brands. I've watched a £14M home goods store burn nine months on what they called "the data cleanup year." Different SKU codes in NetSuite, Shopify, and the 3PL. Three sources of truth, none of them right.
That's not a data problem. That's a normalization problem masquerading as a tooling problem. The fix is to normalize on ingestion, not three months later when the dashboards already lie. For tooling that aligns to this lifecycle, see our roundup of ecommerce management software.
The accrual versus cash trap
Most Shopify operators run on cash basis because Shopify shows cash basis. Inventory losses hide in that view. A 2026-grade lifecycle has to support accrual reasoning, otherwise your "profitable Tuesday" is actually selling €18 SKUs at a €4 loss after returns and fees.
How we cut the cleanup year at Luca
We normalize and standardize on ingestion across Shopify, Meta, Google Ads, Klaviyo, and Xero. The brand plugs in. Asks. Acts. The "data cleanup year" becomes a data cleanup week. That's the only architectural decision that compounds as you scale past €10M. For the operator workflow this enables, see agentic AI for ecommerce founders.
"Daily revenue totals are wrong, entire order blocks are missing, and every week we have to open new support tickets just to get our numbers halfway close to what our channel actually reports." XTRA FUEL Triple Whale Trustpilot Verified Review
When stage two leaks, every downstream stage inherits the rot.
Q3: PIM vs. CDP vs. MDM vs. Warehouse: Which Tool Owns Which Data Stream? [toc=3. PIM CDP MDM Warehouse]
PIM owns product attributes. CDP owns unified customer profiles and identity resolution. MDM owns the golden record across all master entities. The warehouse, like Snowflake or BigQuery, owns the analytical substrate everything else queries against. Most DTC stacks need a CDP plus a warehouse before they need a PIM. MDM only becomes urgent past €20M revenue or 5+ sales channels.
Four categories operators routinely conflate
Credencys' PIM and MDM guide is blunt about the overlap and where each tool stops being useful. OMR's 2025 MDM and PIM bundle adds the practical lens: PIM goes deep on one entity (product), and MDM goes wide across all of them.
Side-by-side, what each tool actually does
PIM, CDP, MDM, and Warehouse: Stream Ownership and Fit
Tool
Owns this stream
Best for
Skip if
Typical entry cost
PIM (Pimcore, Akeneo, Salsify)
Product attributes, taxonomy, and content
500+ SKUs, multi-channel syndication
Under 200 SKUs on one channel
€1,500 to €8,000/mo
CDP (Klaviyo CDP, Segment, RudderStack)
Customer profiles, identity, and segments
First-party retention, personalization
Under €2M revenue, single channel
€600 to €5,000/mo
MDM (Pimcore MDM, Stibo, Reltio)
Golden record across all master entities
€20M+ multi-channel, M&A consolidation
Sub-€20M single-brand
€5,000 to €25,000/mo
Warehouse (Snowflake, BigQuery, Databricks)
Analytical substrate for everything
Anyone past 1M monthly orders
Pre-product-market-fit
€300 to €3,000/mo on usage
Who needs what at which stage
A €3M Shopify brand on one channel does not need a PIM. They need a CDP plus a warehouse, and they need attribution sanity. A €25M omnichannel brand selling on Shopify, Amazon, Faire, and three retail accounts genuinely needs MDM, because the same SKU shows up four times with four IDs.
I've watched founders buy a €60K/year PIM at €4M revenue because a vendor sold them on "future-proofing." Twelve months later the PIM sat empty while the team still reconciled SKUs in Google Sheets. For the analytics tooling that should land before any PIM, see our list of ecommerce analytics platforms.
Where Luca's analytics layer fits
Luca isn't a PIM or an MDM. Luca is the AI reasoning layer that sits over your warehouse and connected sources, extracts the relevant data for whatever situation you're in, predicts based on history, simulates scenarios, finds root causes, and pushes customized reports to Slack or email on a schedule you set. If you don't have a warehouse yet, Luca connects to Shopify, Meta, Google, Klaviyo, and Xero directly. If you do, Luca queries it. See the full data analysis use case for how this looks in practice.
"It has been unable to deliver on the promise to provide any insights or accurate data to our business, and we end up reverting back to direct data sources like Meta, Shopify, Recharge." Matt Huttner Triple Whale Trustpilot Verified Review
"Building with the AI tool Moby is very buggy and crashes more than half the time, and support is largely unresponsive." Matt Huttner Triple Whale Trustpilot Verified Review
How to choose, in one sentence
Pick CDP plus warehouse first. Add PIM when SKU complexity outgrows spreadsheets. Add MDM when you have three or more systems claiming to be the source of truth and someone has to be the referee. If you're still comparing analytics-only options, our Triple Whale alternatives guide breaks down the trade-offs.
Q4: Which Data Integration Patterns Fit a Scaling Shopify Stack: ETL, Reverse-ETL, Pub/Sub, or Event Streaming? [toc=4. Integration Patterns]
Five integration patterns dominate ecommerce: batch ETL (nightly Shopify to warehouse), ELT (raw load then transform inside the warehouse), reverse-ETL (warehouse out to Klaviyo and Meta for activation), pub/sub (real-time inventory across channels), and event streaming (Kafka or Kinesis for behavioral micro-events). Pattern choice should be driven by latency tolerance and downstream action, not by what a vendor sells.
How each pattern actually works
Batch ETL extracts on a schedule, transforms outside the warehouse, then loads. Cheap, predictable, and fine for nightly P&L. ELT flips the order, loads raw first, and transforms with dbt inside Snowflake or BigQuery. Default for modern stacks because storage is cheap and transformation logic stays versioned.
Reverse-ETL is the one most operators underuse. Hightouch and Census push warehouse-modeled audiences back into Klaviyo, Meta, and Google Ads, so your "high-LTV repeat buyer" segment is the same in every tool. Pub/sub keeps inventory consistent across Shopify, Amazon, and retail POS in seconds, not hours. Event streaming captures behavioral micro-events for personalization and fraud, and most sub-€20M brands don't need it yet.
What to detect in each pattern
Batch ETL: nightly revenue reconciliation, finance close, and attribution snapshots
ELT: cohort modeling, contribution margin, and blended ROAS over rolling windows
Reverse-ETL: audience sync, churn-risk flags, and replenishment triggers
Pub/sub: live stock counts across channels, and oversell prevention
Event streaming: session-level personalization, and fraud anomaly detection
Why pattern choice matters in dollars
A €5M brand losing one weekend to oversell on a top SKU loses three things at once: the gross margin, the ad spend that drove the traffic, and the customer who churns to a competitor. Batch ETL was fine in 2018. In 2026, anything you sell across more than two channels needs pub/sub on inventory.
My contrarian take on real-time
Most DTC brands over-engineer real-time when batch suffices. If you're €2M to €8M on Shopify with one fulfillment center, your pub/sub need is exactly two pipes: inventory and order status. Everything else can run nightly. I could be off here, but the pattern I keep seeing is teams paying for streaming infrastructure they query weekly. For the unit economics view, see the best way to track e-commerce unit economics.
Where Luca's analytics layer plugs in
Luca's analytics ingests from Shopify, Meta, Google, Klaviyo, and Xero through managed connectors, normalizes on the way in, and answers questions across the unified layer in plain English. Set an alert: "ping me on Slack if ROAS dips 15% on Campaign 47 or if SKU 8821 falls below 500 units." Luca scans 24/7 and pushes the alert with reasoning attached, not a raw number. The same engine powers our marketing analysis and automation workflows.
That is the difference between a passive dashboard and a system that watches the store while you sleep.
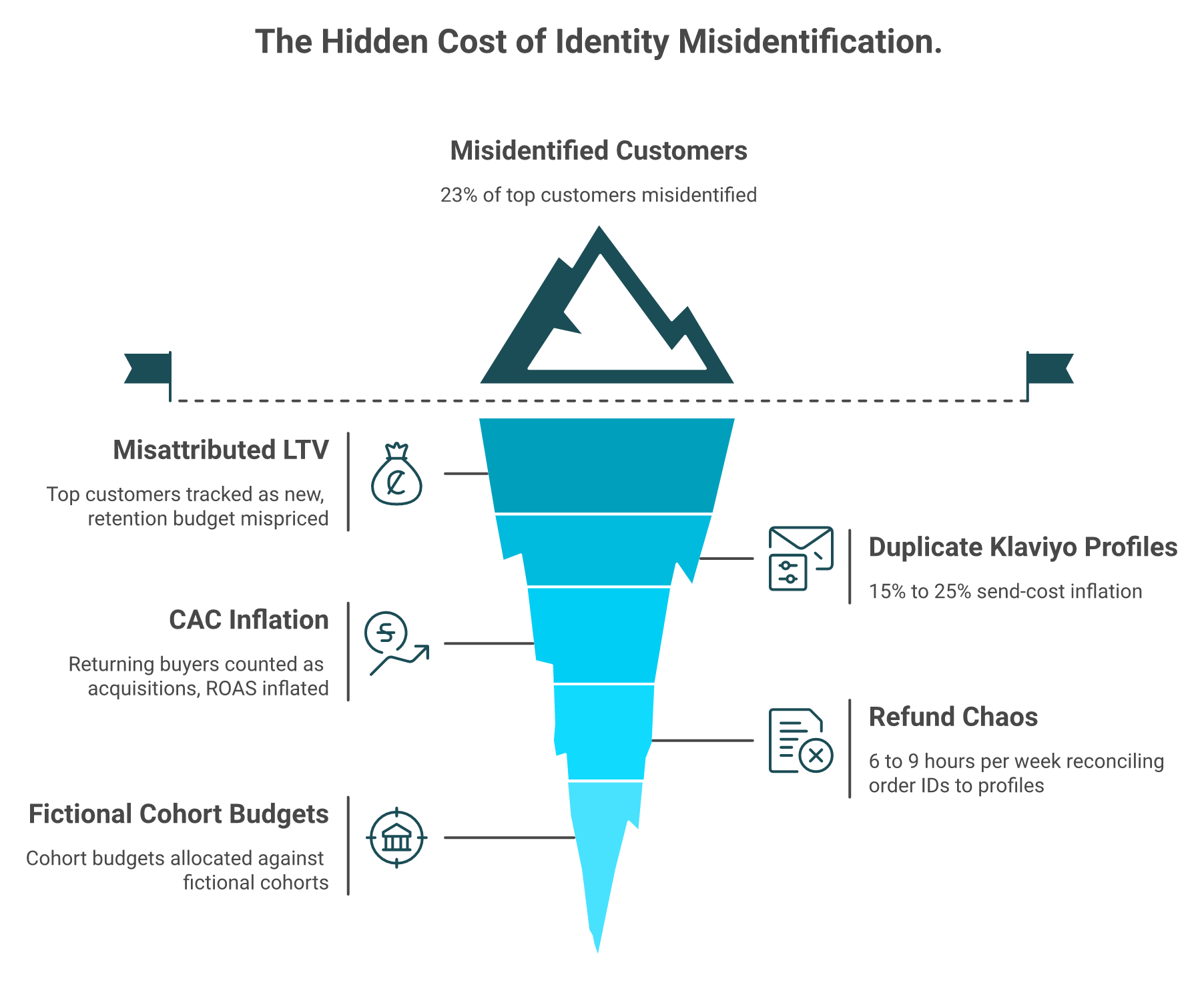
Q5: How Does Identity Resolution Actually Work, and Why Are Brands Misidentifying 23% of Their Best Customers? [toc=5. Identity Resolution]
Identity resolution stitches fragmented signals (email, hashed phone, device ID, and order ID) into one customer record using deterministic matches first, then probabilistic ML when exact matches fail. Research shows consumer brands misidentify up to 23% of their highest-value customers, the cohort responsible for 50%+ of revenue. In a post-cookie world, first-party identity is the foundation of every retention and LTV (lifetime value) decision.
The 11pm scenario every Klaviyo admin knows
It's 11:14 PM. A founder pings the Slack: "Why does Klaviyo say we have 142,000 profiles and Shopify says 89,000 customers?" The CFO is asking why returning-customer revenue dropped 18% week over week. Nobody knows if churn went up or if the system is double-counting.
The answer is almost always identity. The same buyer placed an order as guest in March, signed up with a different email in May, and bought again on mobile in July. Three profiles. One person. Zero clarity. For more on this pattern, see why e-commerce founders are drowning in data.
Why this problem exists in 2026
Cookie deprecation broke cross-device tracking, and operators rebuilt on first-party signals without a stitching layer. Email is still the strongest deterministic key, but cart abandonment, guest checkout, and Apple Mail Privacy Protection mean ~30% of profiles arrive without one.
Probabilistic matching (device fingerprint plus behavior plus geo) fills the gap, but only if you have a CDP or warehouse running the match logic. Most DTC stacks don't. Our piece on ecommerce website analytics walks through the missing layer.
The hidden costs, in money
The 23% misidentification stat is the tip. The real cost compounds through four hidden layers below the waterline.
💸 Misattributed LTV: top customers tracked as new buyers, retention budget mispriced
💸 Duplicate Klaviyo profiles: send-cost inflation of 15% to 25% on most accounts I audit
💸 CAC (customer acquisition cost) inflation: returning buyers counted as acquisitions, ROAS looks better than reality
💸 Refund chaos: support spends 6 to 9 hours per week reconciling order IDs to profiles
How it should work, end to end
A unified customer record uses a deterministic waterfall first: order ID, then hashed email, then hashed phone, then logged-in user ID. If none match, probabilistic ML scores device, IP, and behavioral fingerprints to merge with confidence above a set threshold.
Anthony Mink at Live Bearded ran cohort analysis on a clean unified dataset and found that product category diversity, not purchase frequency, was the biggest LTV driver. He couldn't have seen that with duplicate profiles. For the data infrastructure that enables this, see our data analysis and deep industry research use case.
How Luca approaches cross-stream matching
Luca's analytics layer reads Shopify, Klaviyo, and your warehouse and surfaces the duplicate-profile rate, the unmatched-order rate, and the cohort drift in plain English. Ask: "How many of my top 1% LTV customers are also tagged as new buyers in Meta?" Get an answer in seconds, not a six-week data project. Cohort-level vigilance, without the cohort-level dashboard. Read the AI Co-Founder explainer for the architectural detail.
"Triple Whale shows orders from external marketplaces as if they were real conversions, even though these orders never go through our Shopify store." XTRA FUEL Triple Whale Trustpilot Verified Review
The contrast: from 3-hour manual deduplication on Sunday nights to a 5-second answer when you ask the right question.
Q6: What Does a Realistic Data Quality Scorecard Look Like for a €5M DTC Brand? [toc=6. Data Quality Scorecard]
A working data quality scorecard covers six dimensions, namely accuracy, completeness, consistency, timeliness, validity, and uniqueness, applied across product, customer, and transactional streams. For a €5M DTC brand, three thresholds matter most: under 2% duplicate customer records, under 5% SKU attribute gaps, and under 24-hour refresh latency on revenue dashboards. Below those bars, every downstream model degrades.
☐ Can you answer "what's my true contribution margin by channel" in under 60 seconds?
☐ Is your duplicate customer rate under 2% across Shopify and Klaviyo?
☐ Are 95%+ of your SKUs fully attributed (title, taxonomy, COGS, and weight)?
☐ Do revenue dashboards refresh within 24 hours of the last order?
☐ Does someone own each data stream by name (RACI, not "the team")?
☐ Are returns and refunds reconciled to original orders within 7 days?
☐ Can your team get answers without SQL or analyst tickets?
☐ Do you have automatic alerts for ROAS dips, CAC spikes, or stockout risk?
Score interpretation
Data Quality Scorecard: Interpretation and Monday Moves
Score
What it means
Monday-morning move
✅ 6 to 8
Mature stack, focus on optimization
Add semantic labels for AI activation
⚠️ 3 to 5
Critical gaps, decisions on partial data
Fix duplicate rate and SKU attribution this quarter
❌ 0 to 2
Fragmentation is costing real revenue
Stop new tooling. Fix ingestion and ownership first.
The single-score myth
Most vendor dashboards show one "data health" number. That's lazy. Each stream (product, customer, transactional, behavioral, and inventory) has its own SLAs (service-level agreements). A €5M brand can ship with 90% SKU completeness but cannot ship with 90% order-to-payout reconciliation. Compare options in our roundup of the best Shopify analytics apps.
How Luca closes the gaps
Luca's analytics scans your connected sources, surfaces duplicate rates, attribution gaps, and freshness lag per stream, and pushes weekly Slack reports with reasoning attached. The unchecked boxes turn into specific tickets. The same engine then watches the metrics 24/7, so they don't drift back. See how this plugs into financial management workflows.
Score below 5? That's your data cleanup quarter, not a data cleanup year.
Q7: How Do You Govern Ecommerce Data Without Slowing the Business Down? [toc=7. Lightweight Data Governance]
Governance for sub-€20M brands isn't a 200-page policy. It's three artifacts: a data dictionary on one Notion page, a RACI (responsible, accountable, consulted, and informed) matrix naming owners per stream, and tiered SLAs for refresh latency. Heavyweight governance kills velocity. Zero governance creates the data cleanup year. The middle path is the only sustainable one.
The decision dilemma
Most founders pick one of two extremes. Either they ignore governance until a CFO panics during fundraising diligence, or they hire a consultancy and end up with a binder nobody reads.
Both paths cost the same in the end: lost months and lost trust in the numbers. Our breakdown of ecommerce management software covers the tooling implications.
The wrong way to decide
The common failure is to copy enterprise frameworks (DAMA-DMBOK, ISO 8000) into a 12-person team. They're correct, just sized for organizations 100x larger. The mismatch creates "governance theater" while real silos compound.
The right framework, in seven criteria
Score your governance approach 0, 1, or 2 on each:
Single data dictionary: one source defining every metric (CAC, MER, and contribution margin)
Named owners per stream: product, customer, transactional, behavioral, and inventory each have one human owner
Refresh SLAs by tier: revenue real-time, inventory hourly, and P&L daily
Quality tests on ingest: dbt tests or equivalent run on every load
Access tiers: read, query, write, and admin, mapped to roles
Lineage visible: any number can be traced to its source in under 60 seconds
Change control: schema or metric changes go through one approval channel
Apply the framework
Score 12 to 14: governance is sustainable, scale into it. Score 7 to 11: you have the bones, fill in ownership and SLAs this quarter. Score under 7: you're flying blind, and the numbers in your last board deck are probably wrong. For a forecasting-focused view, see our guide to forecasting cash flow for e-commerce.
The phased path Pimcore actually recommends
Pimcore's MDM roadmap walks brands through discovery, governance, tooling, and activation in that order. Most brands skip discovery, buy tooling, and wonder why nothing works.
How Luca fits the framework
✅ Single data dictionary: Luca anchors metric definitions across connected sources ✅ Lineage visible: every answer Luca returns shows the underlying query and the source ✅ Refresh SLAs: Luca scans 24/7 and pings on Slack when freshness slips ❌ Ownership and access tiers: that's still a human decision, no tool fixes it for you
The meta-insight: governance isn't paperwork. It's the speed at which a question becomes a trustworthy answer. See agentic AI for ecommerce founders for how this changes operator workflow.
Q8: What Does AI Readiness Actually Mean for Your Ecommerce Data, and Are You Ready? [toc=8. AI Readiness]
AI readiness means three things: all five data streams flow into one queryable layer, entities are semantically labeled (product taxonomy, customer cohorts, and channel definitions), and identity coverage exceeds 80%. Of 402 Shopify Plus brands surveyed in late 2025, the majority failed at least one of those criteria. Built-in AI inside vertical SaaS is structurally limited, because it can't see across silos.
The benchmark hook
A late-2025 survey of 402 Shopify Plus brands found most could not answer cross-functional questions in under 5 minutes without a human analyst in the loop. That's the AI readiness gap, in one number.
The brands that closed it didn't buy more vendor AI. They unified the data first. For the tools that close that gap, see our roundup of the best AI tools for Shopify owners.
The benchmark deep-dive
AI readiness has a clean three-part definition operators can self-score:
Unified queryable layer: one place where product, customer, transactional, behavioral, and inventory live and join
Semantic labels: taxonomies, cohorts, channels, and metric definitions are explicit, not implicit
Identity coverage above 80%: most orders and sessions tie to a known customer record
Ari Tulla at ELO Health put the contrarian point in dollars: "We spent $10M building an algorithmic engine, then LLMs arrived and were 10x better." The lesson isn't "don't build." The lesson is: own the data, rent the intelligence. Read more in the intelligence capital thesis.
The founder parallel
Three patterns show up across operators I work with:
Live Bearded discovered category diversity was the real LTV driver only after cohorting on a unified dataset
VAST used weather signals to propose £50k incremental ad spend during a heatwave window, captured because the data layer crossed marketing, inventory, and external signals
Multiple sub-€10M brands report that "native AI" inside their inventory or ERP system is "rubbish" because it can't see ad spend or cash position
Pattern recognition
The pattern is consistent across scales. Brands that win with AI in 2026 do not have better models. They have better-organized data underneath the same models everyone can access. For the operator workflow, see how AI can actually help you run your e-commerce business.
"Building with the AI tool Moby is very buggy and crashes more than half the time, and support is largely unresponsive." Matt Huttner Triple Whale Trustpilot Verified Review
"Daily revenue totals are wrong, entire order blocks are missing, and every week we have to open new support tickets." XTRA FUEL Triple Whale Trustpilot Verified Review
Both reviews illustrate the readiness ceiling. AI bolted onto a leaky data layer inherits the leaks.
The principle and the Luca bridge
Horizontal beats native. A reasoning layer that connects Shopify, Meta, Google, Klaviyo, and Xero sees patterns no single-vertical AI can. We built Luca's analytics on that bet: extract relevant data from a pool, predict from history, simulate scenarios, find root causes, and push customized reports to Slack and email on schedule. Explore the full use cases library to see the patterns in action.
If you score 3 out of 3 on the readiness checklist, you're ready to activate AI agents. If you score 1, fix the data first. The model will not save you.
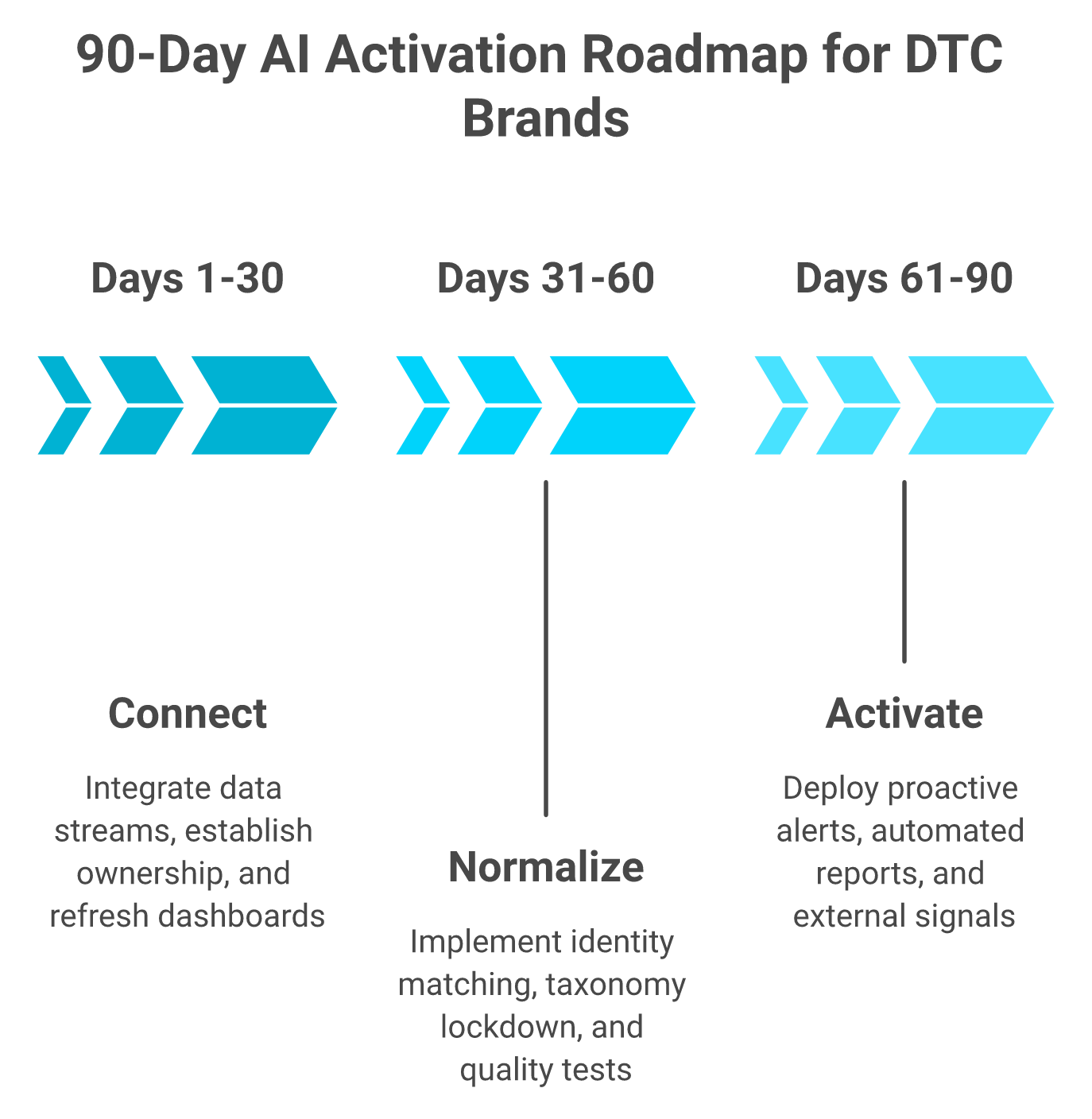
Q9: How Do You Build a 90-Day AI Activation Roadmap From Your Existing Stack? [toc=9. 90-Day AI Roadmap]
A defensible 90-day AI activation roadmap has three 30-day phases. Days 1 to 30, connect all five streams into a warehouse or unified layer. Days 31 to 60, normalize taxonomies and resolve identity. Days 61 to 90, activate AI agents on the clean substrate. Skip phases and the AI hallucinates. Honor them and you compound advantage every quarter.
Three 30-day phases that take a Shopify stack from raw streams to 24/7 AI-driven decisions.
A €3M DTC founder kicks off Day 1
Here's how this actually plays out for a founder doing €3M on Shopify with Meta, Google, Klaviyo, and Xero in the mix. For the broader operator context, see agentic AI for ecommerce founders.
The 90-day timeline
⏰ Day 1, Monday 9:00 AM, Kickoff Inventory the five streams. Name one human owner per stream. Pick the warehouse or unified layer (Snowflake, BigQuery, or a managed analytics layer). No tooling decisions beyond that.
⏰ Day 7, Connectors live Shopify, Meta, Google Ads, Klaviyo, and Xero connectors land in the unified layer. Raw rows only. No transforms yet.
⏰ Day 14, First reconciliation Reconcile yesterday's Shopify revenue against Meta-reported revenue and Klaviyo flow attribution. Document every gap. Most brands find 10% to 25% drift on day one.
⏰ Day 21, Schema mapping Align SKU codes, currency, channel definitions, and customer IDs across sources. This is the step most teams skip and pay for later.
⏰ Day 30, Phase 1 review Single source of truth lives. Revenue dashboards refresh under 24 hours. CFO can defend the numbers in board meeting prep. Compare options in our roundup of ecommerce analytics platforms.
Phase 2: Normalize and resolve
⏰ Day 35, Identity stitching Run deterministic match (order ID, then email, then phone) across Shopify and Klaviyo. Push probabilistic match for the unmatched tail.
⏰ Day 45, Taxonomy lockdown Product categories, customer cohorts, and channel definitions get explicit labels. AI cannot reason across implicit taxonomies.
⏰ Day 55, Quality tests Automated dbt tests on every load. Duplicate-rate alerts on Slack. Freshness alerts on Slack.
⏰ Day 60, Phase 2 review Identity coverage above 80%. Duplicate rate under 2%. Cohorts trustworthy enough to drive retention budget. The same data hygiene unlocks marketing analysis and automation at scale.
Phase 3: Activate
⏰ Day 65, First AI agent Set the first proactive alert: "ping me on Slack when ROAS dips 15% on top campaigns or when SKU velocity drops 20% week over week."
⏰ Day 75, Weekly auto-reports Schedule weekly CAC, contribution margin, and inventory-velocity reports with reasoning attached, delivered to Slack and email. For the cash-flow side of this discipline, see AI for e-commerce cash flow forecasting.
⏰ Day 85, External signals Layer one external signal. VAST used weather data to propose £50k incremental ad spend during a heatwave window. Yours might be Google Trends or a competitor pricing feed.
⏰ Day 90, Phase 3 review The unified layer answers cross-functional questions in seconds. The AI watches the store 24/7. See the AI Co-Founder explainer for the architectural detail.
Before vs. after
Before Day 1: 12 hours per week on manual reconciliation, and a 2-week lag between signal and action. After Day 90: under 90 minutes per week on data tasks, real-time alerts with reasoning, and decisions made the same day they're surfaced.
That's the shift from rear-view mirror analytics to a system that watches the store while you sleep.
Q10: Triple Whale Plus Wayflyer vs. an AI Co-Founder Stack: Which Architecture Wins at €5M+? [toc=10. Triple Whale vs Co-Founder]
Triple Whale shows you the speedometer. Wayflyer hands you fuel. Neither has the GPS. At €5M+ revenue, the architectural cost of stitching analytics-only tools to capital-only providers is 10 to 15 hours per week of manual reconciliation, and a 2-to-3-week lag between signal and action. A unified AI Co-Founder closes that loop in one conversation.
The comparison context
You're evaluating two stacks because they solve overlapping problems through fundamentally different architectures. Triple Whale is an attribution and marketing analytics layer. Wayflyer is a revenue-based-financing (RBF) capital provider. Both leave a gap the founder fills manually. For deeper alternative breakdowns, see Triple Whale alternatives and Wayflyer alternatives.
Triple Whale's approach and limits
✅ Triple Whale aggregates Meta, Google, and Shopify into one marketing dashboard with attribution windows. ✅ The Moby AI assistant answers questions on top of the marketing dataset. ❌ Triple Whale sees marketing, not finance. Cash flow, payables, and inventory don't live in the same view. ❌ Operator reviews flag accuracy gaps that force fallback to direct sources.
"It has been unable to deliver on the promise to provide any insights or accurate data to our business, and we end up reverting back to direct data sources like Meta, Shopify, Recharge." Matt Huttner Triple Whale Trustpilot Verified Review
Wayflyer's approach and limits, on capital metrics
✅ Wayflyer offers fast revenue-based capital with no equity dilution. ✅ Approval cycles can land within days for established borrowers. ❌ Underwriting is opaque, and operators report repeated last-minute reversals on confirmed offers. ❌ Repayment terms can shift mid-relationship, and customer service is inconsistent. For a direct contrast, see Luca AI vs Wayflyer.
"Our experience with Wayflyer has been extremely disappointing and professionally damaging. After being offered funding in writing with specific amounts, repayment terms, and confirmation that the deal was approved, Wayflyer abruptly reversed their decision at the last minute." Geoff Brand Wayflyer Trustpilot Verified Review
"0 customer service whatsoever, I've done 2 loans with these people and can't get a hold of a real person." Trustpilot reviewer Wayflyer Trustpilot Verified Review
Side-by-side, on the dimensions that matter at €5M+
Triple Whale vs. Wayflyer vs. AI Co-Founder Stack at €5M+
Dimension
Triple Whale (analytics)
Wayflyer (capital)
AI Co-Founder stack
Cross-functional reasoning
Marketing only
None
All five streams in one layer
Proactive alerts
Limited dashboard alerts
Manual repayment portal
24/7 scan with reasoning attached
Identity and cohort accuracy
Attribution gaps reported
Not in scope
Deterministic and probabilistic match
Setup time
Medium connector setup
Application and data sharing
10-minute no-code connectors
Capital underwriting transparency
Not in scope
Opaque, reversals reported
Out of scope here, evaluated separately
Manual reconciliation hours/week
4 to 6
1 to 2
Under 1
Who should choose what
Choose Triple Whale if your only question is "how did Meta and Google perform yesterday," and you have an analyst already cross-referencing with Shopify and Xero. Choose Wayflyer if you've vetted their underwriting against your specific scenario and have a backup capital source for last-minute reversals. Compare alternative capital sources via our Clearco alternatives guide.
Choose a unified AI Co-Founder analytics layer if you want one place that reasons across marketing, finance, and operations, scans 24/7, and pushes actionable answers in plain English. Capital underwriting is a separate decision that should be evaluated on its own metrics: rate, disbursal time, and transparency of terms. See the intelligence capital thesis for the architectural argument.
Q11: How Do You Handle the Most Common Objections: Security, Cost, and Switching Risk? [toc=11. Objection Handling]
Three objections kill 80% of data-management upgrades:
Objection 1: "We can't share financial data with AI."
Validate the concern. This is the most common objection, and it's reasonable. You've built the business on data competitors would pay for, and AI training-data headlines don't help.
Address the reality. Modern data layers run SOC 2 Type II certification, AES-256 encryption at rest and in transit, and explicit zero-training data policies. Queries run against your data without storing copies in training datasets. GDPR and CCPA deletion rights are standard. Review our privacy policy for the specifics.
Verify independently. Request the SOC 2 report. Ask for the data processing agreement. Compare the encryption standard to what Stripe and Shopify already require for API integrations.
Objection 2: "Total cost of ownership is unclear."
Validate the concern. SaaS pricing tied to data volume punishes growth. The bigger you get, the more you pay, regardless of value delivered.
Address the reality. Flat-rate pricing decoupled from data volume keeps TCO predictable. A unified analytics layer typically replaces 2 to 4 single-purpose dashboards plus the analyst time needed to triangulate them. The line items to compare are seat costs, ingestion costs, and analyst hours saved per month. See current Luca pricing for the flat-rate model in detail.
"We were rejected. Despite every indication and a past offer that pointed towards us getting another respectable offer." Mike M 8fig Trustpilot Verified Review
That review is about RBF, not analytics. It's the same lesson, though: opaque pricing and opaque underwriting both punish operators after the contract is signed. For more on capital-side patterns, see calculating working capital for ecommerce business needs.
Objection 3: "Migration will break the business."
Validate the concern. A 6-week implementation that breaks your reporting during Q4 is worse than messy data.
Address the reality. Modern connectors run no-code, in parallel with your legacy stack, and on read-only access. The legacy dashboards keep running. The new layer ingests, normalizes, and answers questions without disrupting the live business. If the new layer underperforms, you cut the connectors, and nothing downstream changes. See how Luca troubleshoots process malfunctions for the parallel-run pattern.
Verify independently. Run a 14-day parallel pilot on read-only credentials. Compare answers. Switch only when the new layer is consistently more accurate and faster than the manual workflow. To start the conversation, contact our team.
The pattern across all three objections is the same. Specifics beat platitudes. Verification beats trust.
FAQ's
What is ecommerce data management in 2026, and why has the definition changed?
We define ecommerce data management as the discipline of capturing, normalizing, governing, and activating five streams, namely product, customer, transactional, behavioral, and inventory data, into one reasoning layer the business can act on.
The 2026 shift matters because data is no longer just a reporting asset. It is the substrate every AI agent reasons against.
Old definition: ETL into a warehouse, build dashboards on top.
New definition: a single source of truth above PIM and CDP, structured so AI can join entities and act in plain English.
For founders running €1M to €100M on Shopify, the practical implication is simple. If your five streams are not unified, your AI hallucinates and your decisions lag by two to three weeks. We unpacked this in our breakdown of why e-commerce founders are drowning in data.
How does identity resolution work, and what does it cost when it fails?
Identity resolution stitches fragmented signals (email, hashed phone, device ID, and order ID) into one customer record. We run deterministic matches first, then probabilistic ML for the unmatched tail.
When this layer is missing, consumer brands misidentify up to 23% of their highest-value customers, the cohort responsible for over 50% of revenue.
Misattributed LTV: top customers tracked as new buyers, retention budget mispriced.
Duplicate Klaviyo profiles: send-cost inflation of 15% to 25%.
CAC inflation: returning buyers counted as acquisitions, ROAS looks better than reality.
Refund chaos: 6 to 9 hours weekly reconciling order IDs to profiles.
We built our analytics layer to surface duplicate-profile rates, unmatched-order rates, and cohort drift in plain English. See the full data analysis use case for how this looks on a live store.
Do we need a PIM, a CDP, an MDM, and a warehouse, or can we skip some?
Most DTC stacks do not need all four. We typically recommend CDP plus warehouse first, then layer PIM and MDM only when complexity earns them.
PIM: owns product attributes, taxonomy, and content. Worth it past 500 SKUs across multi-channel syndication.
CDP: owns unified customer profiles and identity resolution. Essential past €2M revenue.
MDM: owns the golden record across all master entities. Becomes urgent past €20M revenue or 5+ sales channels.
Warehouse: owns the analytical substrate everything else queries against.
I have watched founders buy a €60K per year PIM at €4M revenue because a vendor sold them on future-proofing. Twelve months later the PIM sat empty while the team still reconciled SKUs in Google Sheets.
What does a 90-day AI activation roadmap look like for an existing Shopify stack?
We run a three-phase, 30-30-30 day plan that any €1M to €20M brand can defend to its CFO.
Days 1 to 30, Connect: inventory the five streams, assign one human owner per stream, and land Shopify, Meta, Google Ads, Klaviyo, and Xero connectors in a unified layer.
Days 31 to 60, Normalize: deterministic plus probabilistic identity matching, taxonomy lockdown, and dbt quality tests on every load. Target 80%+ identity coverage and under 2% duplicate rate.
Days 61 to 90, Activate: first proactive alert (ROAS dips 15%, SKU velocity drops 20%), weekly auto-reports with reasoning attached, and one external signal layered in.
Before Day 1, operators spend 12 hours per week on manual reconciliation. After Day 90, that drops below 90 minutes. For the operator workflow, see agentic AI for ecommerce founders.
Why is Triple Whale plus Wayflyer not enough at €5M+, and what wins instead?
Triple Whale shows you the speedometer. Wayflyer hands you fuel. Neither has the GPS.
At €5M+ revenue, stitching analytics-only tools to capital-only providers costs 10 to 15 hours per week in manual reconciliation and a 2-to-3-week lag between signal and action.
Triple Whale sees marketing, not finance. Cash flow, payables, and inventory live elsewhere.
Wayflyer sees revenue, not operational context. Operators report opaque underwriting and last-minute reversals.
The founder absorbs the triangulation cost between them.
A unified AI Co-Founder stack reasons across marketing, finance, and operations in one conversation, scans 24/7, and pushes answers in plain English. See our head-to-head in Luca AI vs Wayflyer and the analytics-side comparison in Triple Whale alternatives.
Enjoyed the read? Join our team for a quick 15-minute chat — no pitch, just a real conversation on how we’re rethinking Ecommerce with AI - Luca
Loading Schedule...
Your AI Co-Founder is here.
Here’s why:
Shopify, Meta, Xero - one brain.
"Should I scale?" Answered with real data.
Growth capital. No applications. One click.
Thank you! Your submission has been received! Please book a time slot for the Meeting
Oops! Something went wrong while submitting the form.